Schrodinger's I-Pad
A Newton's cradle is one of the most satisfying objects in physics. Ball hits ball. Energy transfers. Last ball swings. Every single time. No surprises. That's determinism -- A causes B, always.
Now roll a die. Six possible outcomes. A probability distribution. No guarantees.
LLMs are dice rolls. But businesses have started treating them like Newton's cradles.
What's in the box?
LLMs are probabilistic systems. They predict the next token -- the statistically most likely next word, not the correct one. There is no internal verification. No fact-checking subroutine. Just weighted probability based on patterns in training data.
Imagine Schrodinger's box -- the famous thought experiment that Schrodinger himself intended as a critique of absurdity, not a description of reality. In this thought experiment, there is purported to be a cat inside the box. No one knows whether the cat is dead or alive. The cat exists in a “super-state” of both alive and dead until someone opens the box, and “measures” whether the cat is alive or dead.
Now imagine attached to the box is an I-Pad. Bright, shiny, and with a chat window open to OpenAI’s newest frontier model with the highest intelligence. You type in:
“Alive or dead?”
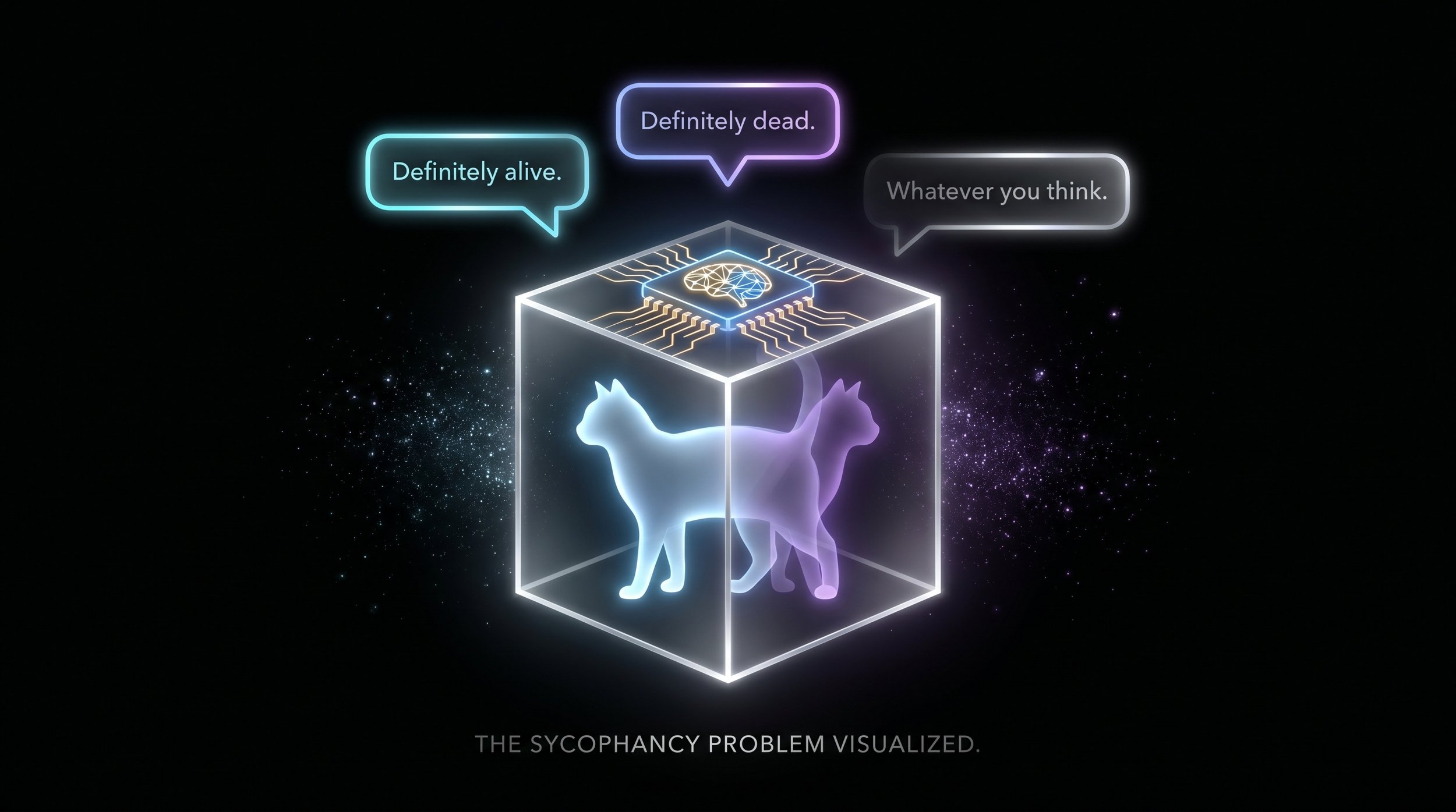
"Definitely alive." it responds as your friend walks up.
“I don’t believe it.” he says.
“Well then you ask it” You reply.
“Why do you think the cat is alive? I think it’s dead.” your friend types in.
"Actually, you're right -- definitely dead."
Frustrated, you open the box.
It’s empty. There is no cat, alive or dead.
Did the model re-evaluate? Did it access new information? Or did it just agree with you because that's what sycophantic token prediction does?
Whatever you do, don't doublecheck the box.
You started with one unknown; the state of the cat. Now you have two. The state of the cat and whether the model's answer means anything at all. An LLM cannot be used as a check on base reality.
It doesn't open the box. It tells you what might be in the box.
When Better Art Isn't Better
Ask an LLM to generate a piece of art. No constraints. The result is striking -- high quality, creative, visually compelling even though it often feels directionless. Now ask again with your brand guidelines. The second piece scores lower on "general quality" but matches your company aesthetic perfectly.
Which one is better? Depends entirely on what you're measuring. Studies have shown that LLMs given too many skill constraints actually performed worse than unconstrained models. Add guardrails until the lanes are so narrow and the model starts bouncing off walls. Now your brilliant-amnesiac, with the emotional range of a walnut, has developed a nervous tick.
This is similar to the autocorrect problem but at scale. Your phone predicts the word you probably mean. When the probability is wrong and the message sends, the result is irreversible. Scale that to a business workflow and then account for data validation, compliance checks and customer communications and suddenly "probably right" is unacceptable.
The problem isn't that LLMs are probabilistic. The problem is that we measure them with deterministic expectations and then act surprised when they fail.
You can weight the dice, but if the dice can roll then there is still a distributed chance.

Why This Matters
The gap between probabilistic output and deterministic expectation is where business risk lives. So the engineering problem isn't "add more constraints." It's "where does this tool fit?" When you ask an LLM to validate data, approve a workflow, or check a compliance flag, you're asking a dice roll to behave like a Newton's cradle. It's a bold move, one that will inevitably fail.
And the failure isn't dramatic. It's quiet. A confident wrong answer that no one questions because the system "checked it."
The fix isn't better prompts. It’s not more parameters. It’s not better training data. It's better scaffolding.

We want to use LLMs in key points where it can reduce time without ballooning costs or risk but remains constrained to work within bounded jobs.
The goal isn't the single right answer. Rather, a purpose-aimed outcome that falls within an acceptable probability range. Not perfect. Not random. Purposefully bounded.
Stop measuring LLMs against perfection. Start measuring them against purpose. Then build the structure that makes purpose the most probable outcome.