From Knowing to Doing
You can't successfully automate the unknown. And you definitely can't hand it to an AI agent that doesn't understand the process it's supposed to execute.
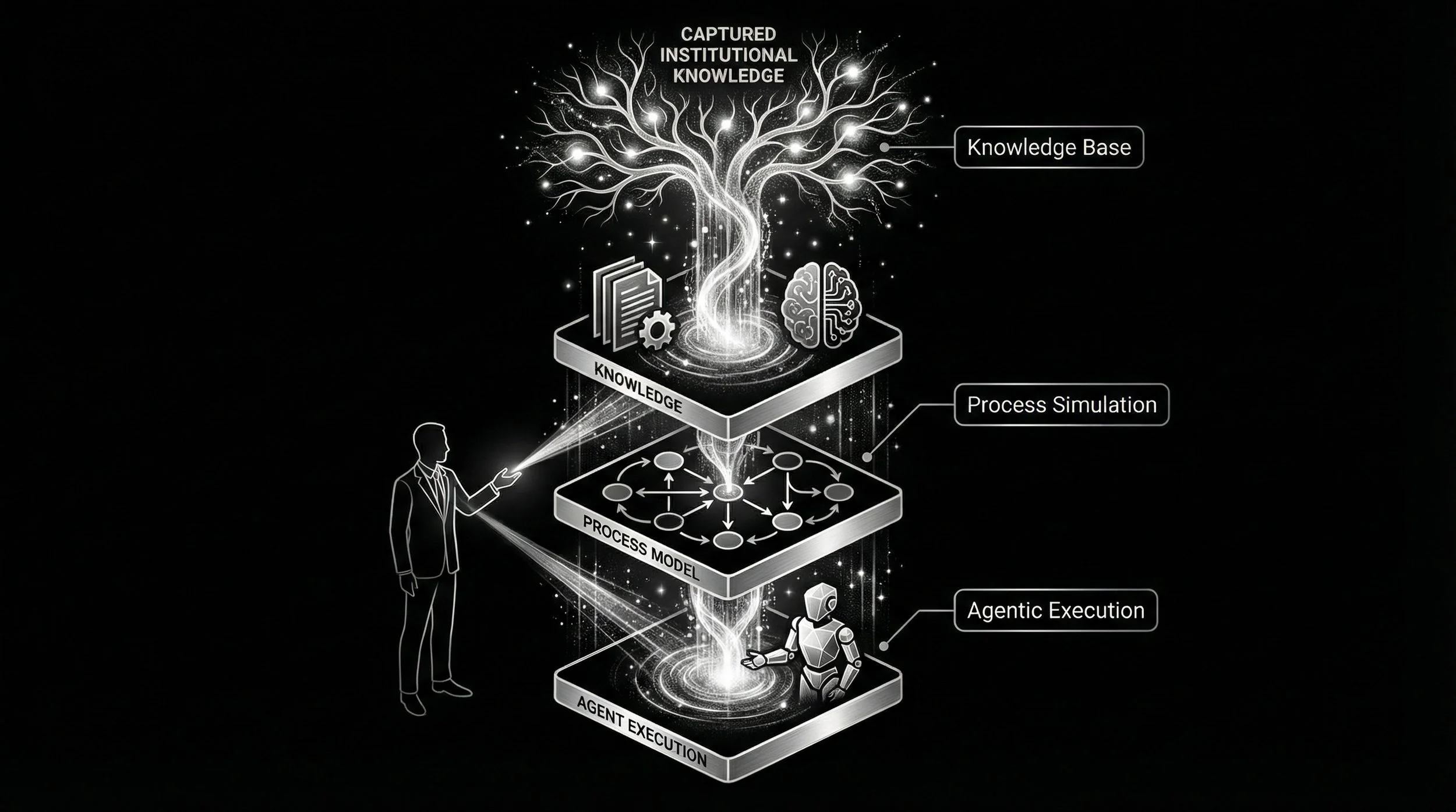
In Parts 1 and 2, we covered the tacit knowledge problem and how to extract what people actually know. Now comes the payoff: turning that captured knowledge into visual models, running experiments before you disrupt your team, and building AI agents that are genuinely informed by the way your organization works.
Process Maps Beat Paragraphs
Scale is hard to capture in words. In a well-designed visualization scale is obvious.
Graphs surface connections and relationships that paragraphs cannot. When you map extracted knowledge into process models, feedback loops become visible. Places where outputs feed back into inputs, creating reinforcing or balancing dynamics that no written document would reveal. This is why firms like McKinsey hunt for leverage points: the specific nodes where a small change creates outsized impact, where loss is accumulating or gain might be captured.
Once you have the model, you can run Monte Carlo simulations against different process configurations without touching a single live workflow. You experiment on the map, not on your people.
Experiment Before You Roll Out
The common failure mode looks like this: change the process, change it again three days later, change it again the following week. Trial and error that frustrates employees and erodes trust in leadership.
Modeling solves this. Consider the small business owner sitting down on a Saturday night, thinking about how to grow the shop and organize his six employees. With a tested process model, he can run experiments against different configurations and hand his team a validated plan on Monday, not a guess.
At enterprise scale, the same logic applies. Department heads identify key leverage points. The VP observes organizational development over time. And new employees get pointed to an exact process map with filtered, relevant documentation instead of a Teams note with twelve unfiltered links and a prayer.
Agentic Adoption: Only After the Foundation
Agents are easily poisoned, frequently distracted, and often misinformed on the nature of their task. This is not a criticism of the technology. It is a consequence of poor inputs.
The knowledge base you built in Parts 1 and 2 becomes the input layer. Extracted, vectorized institutional knowledge informs execution paths. Without it, you are asking an agent to navigate a building with no blueprint.
The human-AI teammate dynamic is an art informed by complex systems thinking. The core competency is knowing which pieces to offload to the agent and how closely to monitor it. The system must facilitate optimal agent performance and sustainable human functioning, not one at the expense of the other.
And the relationship is bidirectional. The agent transforms documentation and surfaces insights. The knowledge base directs the agent's task pursuit. They inform each other continuously.

Purposeful Friction
Not all friction is bad. Some of it is by design.
Wherever an action is irreversible, or where reversibility would be costly and consequential, that node demands a human checkpoint. The aphorism holds: measure twice, cut once. You want assurance the cut will not have to be repeated.
Agents should be airlocked away from essential systems, their capabilities scoped precisely to the desired task. The agent's story must have a deterministic ending, even when the system generating it is generative. And the employee constructs the agent, not the other way around. The human remains the architect.
The Series in Three Sentences
The tacit knowledge problem is not going away. But the tools to solve it are here. Extract what people know. Model what they do. Then, and only then, build agents that can help.
The employee constructs the agent. The knowledge informs the system. And the organization gets stronger, not more fragile, with every iteration.